
What "GPT" actually means
and the building blocks of AI

In this Substack, I’ll share insights and analysis on frontier technology. You’re getting this email because you’ve subscribed to my newsletters in the past about Voice Interfaces, AI & NoCode, or joined one of my Product Roundups at Betaworks. And earlier this year, I started Factorial, which has a focus on AI (more info at the bottom). If you aren’t interested, no hard feelings if you unsubscribe.
A way to understand where AI is going
Is the current state of AI a floor or a ceiling, and what types of use cases can we expect over the next 5-10 years? Understanding how we got to the current point in AI can help us understand the answer to this question.
How we got to now
The following is a highly simplified view that I think is helpful in understanding the innovation that led to today’s state of AI. Purists will say I’m simplifying and leaving things out, which is accurate.
Facial recognition has been around for a while. Researchers figured out that rather than use if-this-than-that type coding, they could mimic the structure of the brain: a neural network. At a really high level that means you have a layer of inputs, a bunch of connections to other neurons (the arrows) that send data from one neuron to the next, and then eventually an output.
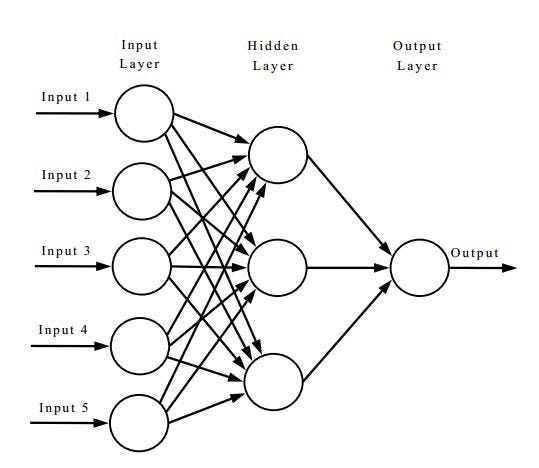
Source: https://tex.stackexchange.com/questions/132444/diagram-of-an-artificial-neural-network
What’s not shown in this diagram is that each arrow also has a weight which helps the neuron understand if input 1 should be more heavily emphasized than input 2, etc. Each individual “artificial neuron” looks something like this:
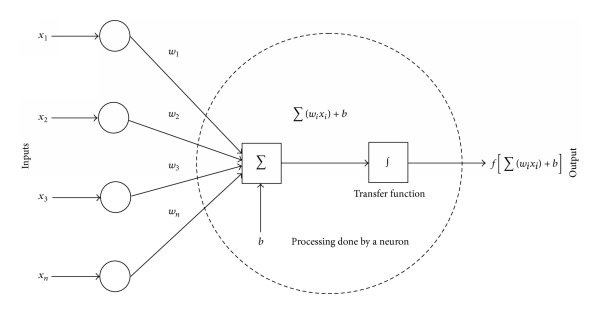
Source: https://www.researchgate.net/figure/Mathematical-model-of-an-artificial-neuron_fig3_268152411
How It Works
Let’s say you have an 8x8 pixel image, which is 64 pixels so you have 64 inputs.
The neural network takes each one of those inputs and multiplies it by the weight (“w” in the diagram of the neuron above). The output of that neuron is then multiplied by a weight and the process repeats as input into the next neuron. As we saw in the first diagram, eventually there is a final output neuron. An example of that output might be a 1 if the image was of a face, and 0 if it’s not a face.
“Training the model” means adjusting the weights
What it means to “train the model” is to adjust the weights until it gives you the output you want. The weights start out as random numbers. Then you use test data (e.g. a bunch of faces and not faces where you know whether the output should be a face or not).
If the output is correct (e.g. it says 1 and it’s correctly identifying a face) then the weights are correct and you can make the high ones even higher and the low ones even lower. If the output is wrong, you lower the high weights and raise the lower weights.
It’s pretty crazy that we basically said, “here’s how the brain works maybe this will work for detecting faces” — and it did!
That research had existed for a while but really accelerated 2000-2010, and these models turned out to work not only for facial recognition but for handwriting recognition, X-rays — basically for anything where you had an image and a set of labeled data.
GANs (Generative Adversarial Networks)
So now it’s 2014-ish and someone has a cool idea: since we have all these trained models to detect images, why not see if we can GENERATE images. Here’s how that worked with a GAN:
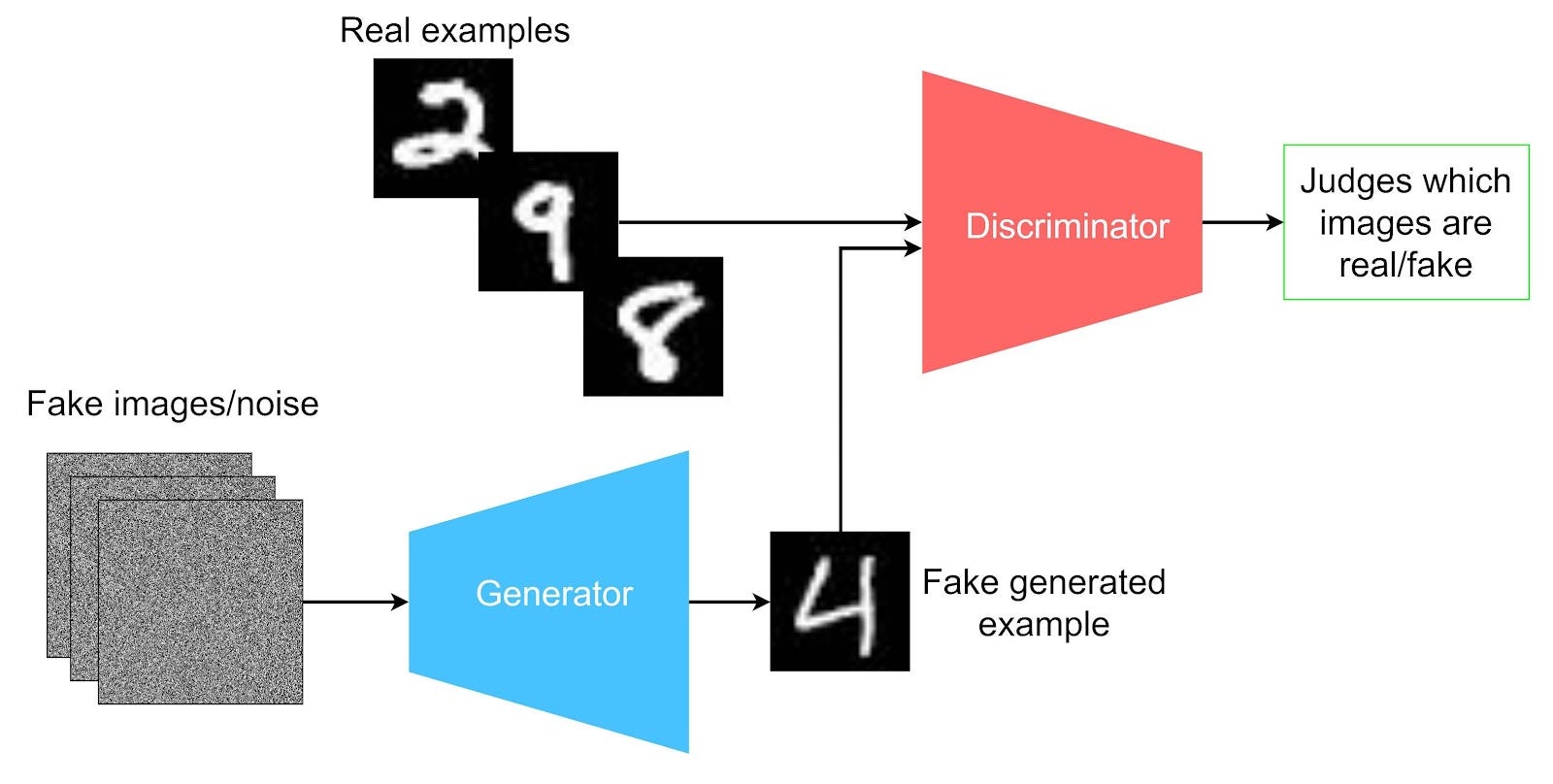
Source: https://developer.ibm.com/articles/generative-adversarial-networks-explained/
What you see is two models fighting with each other. One is the Generator and the other is the Discriminator, which together are the “adversaries” in our Adversarial Network.
Here’s how it works: the Generator starts out with random weights (remember the weights from our model before). So at first, it just produces noise. But the Discriminator is already trained to detect something pre-defined (in the example above, it’s trained to detect numbers). The Generator keeps generating things and the Discriminator keeps saying “no that’s not a number” and the weights are adjusted (automatically).
This turns out to work — eventually the Generator is trained to generate images of numbers. This works not only with images of numbers but with peoples faces. Those Deep Fakes you’ve been seeing were actually trained by a face detection model.
There’s one big problem. Deep learning works well with images (faces, x-rays, etc) but there’s a problem with words: they have meaning beyond simply what the letters are. So you can’t simply put words into a neural network.
So while all this GAN stuff is going on people start looking at this cool new paper which was also simultaneously published as a library for developers. It’s called Word2Vec.
Word2Vec
Word2Vec stands for “word to vector.” A vector is just a directional arrow. What Word2Vec did was convert words into numbers in a way that meant you could plot them on a graph and the distance between two of those points was the vector. What’s CRAZY is that if you took the directional arrow that pointed from Madrid—>Spain and moved that arrow to start at “Rome” it would point to “Italy.” In this case the arrow represents the meaning of what we think of as a country’s capital. Here are some examples from the original paper:

Source: https://cnkndmr.gitlab.io/others/en/neural-network-word2vec.html
This means we can now encode meaning, not just the letters of the words. The output is a graph that contains all the words and is called a “vector database.” The encoding of a word as a point in the graph is called an “embedding.”
Transformers
Transformers are just one type of embedding. What’s pretty cool about them is that they use a lot more than just the word: they can embed the word within various contexts. For example, “I drew a jack from the deck” will create an embedding for “jack” which is distinct from “the tire was flat but we had a jack.” At a really high level, transformers do this by paying “attention” to the words around the key word we’re looking for.
How Embeddings Are Used
So text embeddings (and particularly transformers) turned out to be as exciting for words as GANs were for images – because they worked! The models could be trained to work in a few useful categories:
Translation (e.g., train it on English words to output Spanish words)
Summarization (e.g., train it to take a page and summarize it as a paragraph)
Sentiment Analysis (e.g., tag a sentence as happy or sad)
Categorization (e.g., tag a sentence as being about a particular topic)
Text Generation (e.g., predict the word most likely to come next)
Each of these use cases could be specifically trained as a model, but training a model to do two of these things often limited its ability to do either of them well.
Large Language Models
In our earlier image example, I said if it was an 8x8 image, that meant it was 64 pixels, so you needed 64 unique inputs. In the context of deep learning models these would be called “parameters” (64 parameters are passed into the model as input).
OpenAI asked a really interesting question: what if you used the Text Generation model described above (the one that predicts the word most likely to come next) and trained it on millions of parameters? Nobody had tried that yet, they had used as few inputs as they needed because doing the actual training required lots of GPUs (Graphics Processing Units; read: money, processing power, time).
That’s exactly what OpenAI did. They trained a Generative model with 117 million parameters. OpenAI called this “GPT” because it was a Generative model (versus summarization, classification, etc), it was “Pre-trained” (they’ve already trained it so the weights are already set) and it used Transformers (the type of embedding).
They trained GPT-1 on the BookCorpus data set which has all of the text from about 11,000 unpublished books. So what happened?
Something pretty unbelievable... Many other model use cases (translation, summarization, classification, etc) which previously had to be trained individually were all possible in OpenAI’s resulting model.
OpenAI’s underlying model was a text generation model, but if you wanted to translate, it would still work because it had been trained to predict the next word:

Note that the above is an actual screenshot from OpenAI. It’s just a text box where you can type anything in and click “generate” (there are some knobs you can use to adjust the output).
Is OpenAI Open?
GPT-2 used 1.5 billion parameters and was trained on text from 8 million webpages, which improved performance. Importantly OpenAI released the model for GPT-2 publicly, including the weights. This meant it was truly “open.” They had presumably spent millions of dollars training this model, and they released the weights that resulted from training the model. Because it was public, you could create your own version of it and use it for free.
OpenAI trained GPT-3 with 175 billion parameters (again 10x of the prior model), and trained it on even more data such as Wikipedia, Reddit, and over 3 billion webpages and even more books.
The model provided notedly better answers, but this time they did not release the model or the weights publicly. This allowed OpenAI to charge for use since the only way to access it was through OpenAI.
ChatGPT
Note that OpenAI launched GPT-3 way back in 2021. Engineers thought it was really cool but nobody outside of tech really understood it.
They made a small tweak: rather than make this for developers where you can type into a text box and press “generate,” they released it with an interface that looked like a “chat.” Every time you type into the chat, it’s just like typing into that text box. The one key difference is that behind the scenes it does something like adding to your entry “hey, before this, the user typed [your prior text and its prior answer]” to give it a bit of context.
Open Source
There are now models being released nearly every day, often as “open source” meaning they publish with the underlying code and sometimes the weights. Some of these live on GitHub (a place for developers to share code) and Hugging Face (which specializes in storing the weights and letting you run your models directly on their infrastructure). The GPT-2 model and weights are still public on Hugging Face. New models come out so frequently that someone has made an LLM leaderboard.
The number of open source projects seems infinite. Here are some varied examples:
Listen to a song and tag it with its genre
Question & answering from a PDF
Image captioning
Generating code
Classifying pictures of food
Chat about medical conditions
Generate an image of you and a friend
Generate Jazz music based on language describing the mood
Fine-Tuning A Model
When you’ve trained something on a whole lot of data, you can create a very good generalized model, but you may need something more customized. Rather than creating a model from scratch, which requires millions of parameters, often you can “fine-tune” a model with just a few new data points. For example, if you like the image generation model, but always want it to be generating an image of your face, you could fine tune it with just 15 pictures of yourself and it works pretty well.
Another example is a model that does voice generation, which could be fine tuned to a specific person’s voice with 20 minutes of audio (or maybe less) versus hours and hours of audio that was used to train the underlying model.
Okay this kind of makes sense, now where are things going?
Changing your mindset to think not about databases like Excel, but about unstructured vector databases, is a bit like imagining what you could do with an iPhone in 2008 when it launched.
There are the descriptions of its features: GPS, camera, Bluetooth, Internet connected. There are also descriptions of how it’s used: people tend to hold it in one hand, they tend to use it for short moments in between things while they’re waiting in line, etc.
Since 2008, software developers have experimented by observing people’s use of the iPhone and figuring out ways to create new products native to that experience.
Examples of product insights:
The game Flappy Birds was designed to be played with one hand using only your thumb so you could use your other hand to hold on to the subway poll.
Instagram put a big “+” in the bottom center to make it very easy to take a picture.
Snapchat didn’t even bother with the “+” button, and when you open the app it just directly opens to the camera.
Foursquare built an app for people going to restaurants designed to be used while they were there versus Yelp, which had been designed to be used before and after going there.
We are still in early innings of figuring out what the product insights will be on how to use large language models and other types of AI. We have to see both what’s possible and then also how people will use these new features.
It’s AI until you understand how it works; Then it’s an Algorithm
Right now one of the scary things is that we don’t really understand why these very large neural networks do what they do.
One point of view is that they’re just like our brains – and if you believe our brains are biological versions of computers, then it’s possible for us to build neural networks that are a lot like humans. This is the conversation around “artificial general intelligence” or AGI. “General” here refers to the idea that you don’t have to train different models to do different things, but if you put enough parameters in to train a model, it will be able to do anything — just like a human being.
However there have always been algorithms which create surprising and impressive results, and which require explanation. Today there are a number of companies working specifically on helping coders see inside neural networks to help identify the causes of surprising responses and provide AI explainability.
Should we be afraid of AI?
Software is intertwined in our lives and can behave in a way the developers didn’t intend (e.g. stock-trading algorithms selling for illogical reasons). Typically this is observed and corrected. The difference with AI is that the outcomes are “stochastic” (uncertainty associated with the outcome) not “deterministic” (consistent answer, like a calculator). This makes them less predictable.
But just because the answers are stochastic doesn’t mean they are inherently dangerous. It does make it really important that we understand how the algorithm made a decision so that when we don’t agree with it, we can adjust how it works. This does require a different approach than in the past, and it’s a reason to approach integrating AI into decision making with caution — but not with fear.
Earlier this year, I spun a new fund out of Betaworks: Factorial is the first of its kind multi-manager early stage fund. We partner with a handful of successfully exited founders (and some who are still operating their late stage companies), each with a specific area of expertise. I’m starting with people I backed while at Betaworks who have sold their company or reached escape velocity.
AI is our first practice area given my experience in the category as both a coder and an investor in AI since 2016. We’ve started to be a bit more public about Factorial: Hugging Face CEO teams up with newly launched venture firm Factorial to invest in AI startups and we’ll share more of our teammates soon.
Great material, I've started to recommend your Newsletter.